


英特尔发布锐炫A系列独显:相比核显游戏性能大幅升级,内容创作效率翻倍增加
2022-3-30 23:01
【天极网笔记本频道】在年初的CES 2022展会上英特尔分享了代号为Alchemist的英特尔锐炫显卡的最新进展,将被包括笔记本、台式机在内的超50款设备采用。在2月份英特尔2022投资者大会上,英特尔再次表示ARC锐炫显卡按计划出货。
3月30日23点,英特尔正式公布了首批亮相的锐炫显卡详细信息。英特尔表示,锐炫A系列高性能移动端独立显卡包括覆盖主流游戏的锐炫3系列、性能游戏的锐炫5系列以及硬核性能游戏的锐炫7系列。

首款搭载英特尔锐炫3系列显卡的笔记本已经开始预售,搭载锐炫5/7系列的笔记本,包括游戏本,预计在今年夏天上市。英特尔锐炫A系列全部基于Xe HPG架构打造,包含通用架构和高级功能集并且支持DX12 Ultimate,还拥有强大的AI引擎和增强的媒体引擎。英特尔还为锐炫A系列打造了下一代Xe显示引擎和新的图形管线,用来处理各种不同显示任务。
既然是面向移动端的产品,笔记本的产品形态以及应用场景自然是也是多元化的。为了满足不同产品需求,英特尔锐炫A系列SoC有两种规格,其中ACM-G10的面积更大,包含32个Xe内核和32个光追单元,16MB L2缓存,256bit GDDR6接口,16路PCIe 4.0接口。ACM-G11的面积较小,拥有8个Xe内核和8个光追单元,4MB L2缓存,96bit显存接口,8路PCIe 4.0。
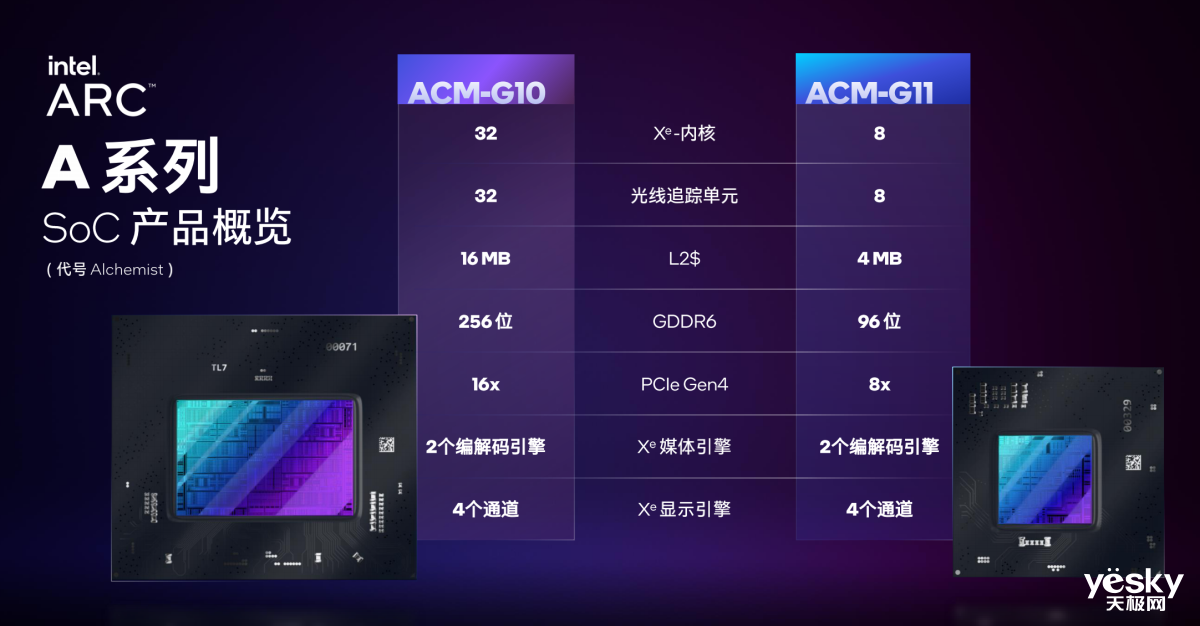
ACM-G10以及ACM-G11芯片均包含2个Xe编解码引擎和4路Xe显示引擎。
不仅是新品设计,既然是移动端产品就不可避免的要谈到功耗。英特尔表示锐炫A系列显卡支持实时监控性能指标,从而东条调节时钟频率。并且,锐炫显卡运行不同负载,或同一负载的不同阶段,其频率、占用率指标都是动态的。英特尔通过选择有代表性负载进行测试后,制定接近真实应用场景的平均时钟频率作为参数配置中的定义标准,从而在宽泛TDP限制下优化时钟频率分布,改善效能。
本次公布的新品方面,锐炫3系列属于移动级独立显卡,主要面向轻薄型笔记本,后续上市的锐炫5系列、锐炫7系列将覆盖到游戏本。

首发的锐炫3系列包括A350M和A370M。A350M拥有6个Xe内核、6个光追单元,显存为64bit位宽的4GB GDDR6,显卡时钟频率1150MHz,功率为25-35W。A370M拥有8个Xe内核、8个光追单元,显存同样为64bit位宽的4GB GDDR6,显卡时钟频率1550MHz,功率为35-50W。
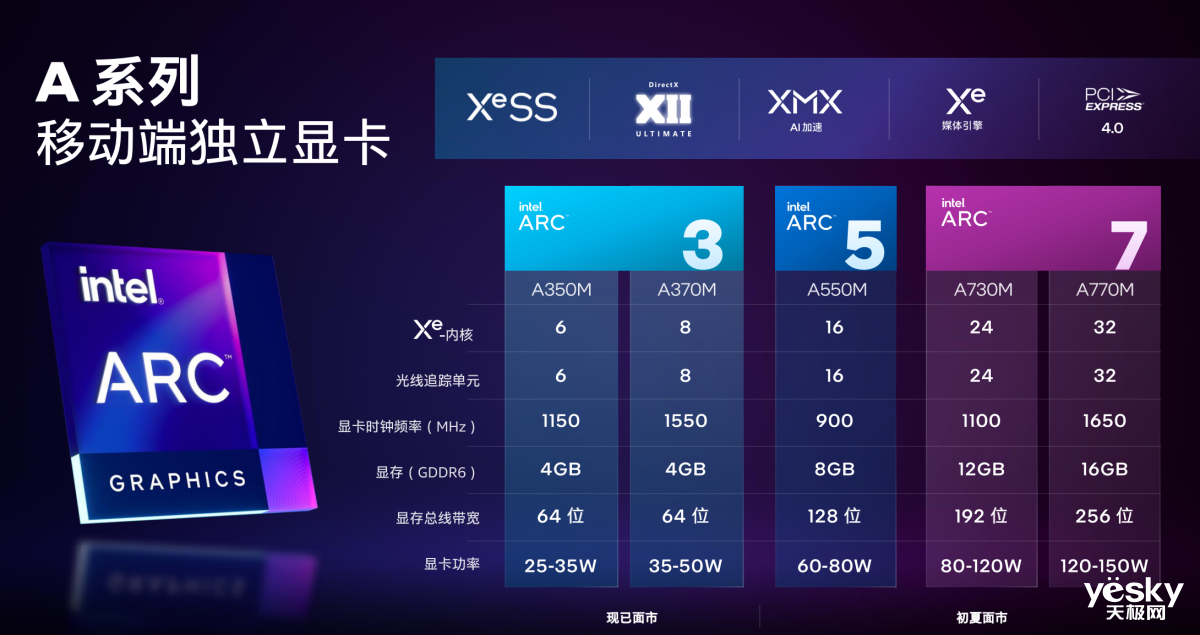
英特尔还公布了将于初夏上市的锐炫5系列――A550M,锐炫7系列――A730M、A770M的规格。
值得一提的是,英特尔Evo设计也可以配备锐炫独立显卡,在保证Evo即时唤醒、长续航、快充、可靠连接等特性的同时,带来2倍的游戏体验升级、XeSS增强游戏体验、XMX增强创作体验等等全新优势。

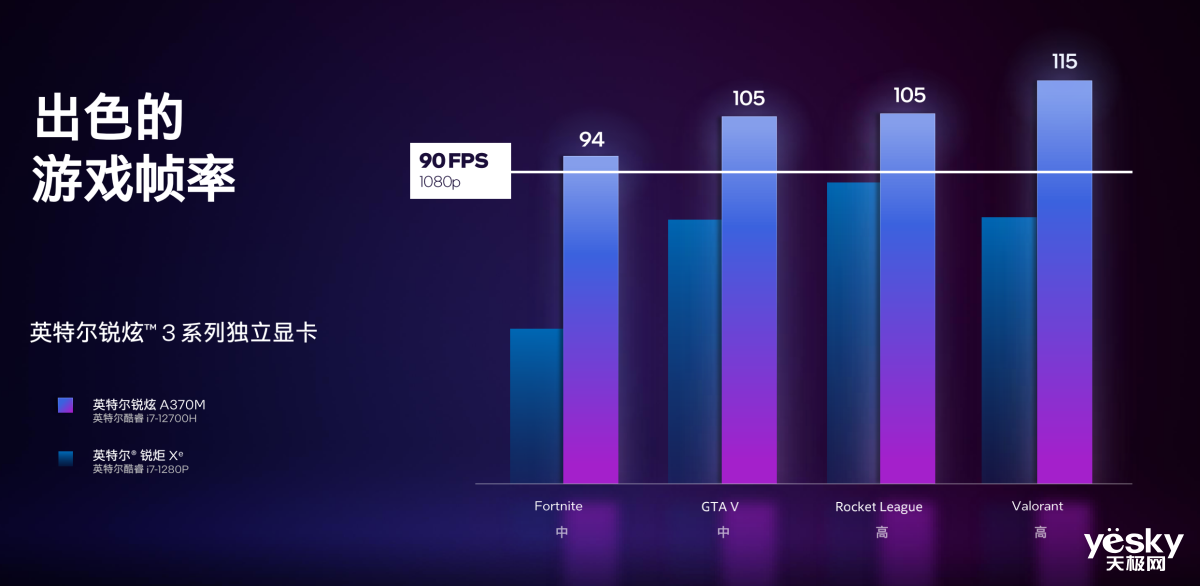
英特尔也公布了一些锐炫3系列独显的性能表现。在游戏场景中,锐炫A370M(搭载酷睿i7-12700H处理器)能够在中高画质下维持60帧以上运行《杀手3》、《毁灭战士》、《全面战争:特洛伊》、《F1 2021》、《帝国时代4》、《命运2》等游戏,相比搭载锐炬Xe核显的12代酷睿轻薄本,性能有明显提升。

另外,在一些热门网游、主流游戏中,锐炫A370M甚至可以提供平均帧数在90、100以上的流畅体验。对于用户而言,可以将搭载锐炫3系列显卡的轻薄本看作是比常规轻薄本性能更强的“全能本”,或者是创作本。因为不仅是更强劲的游戏性能,内容创作也是英特尔锐炫显卡的一大亮点。
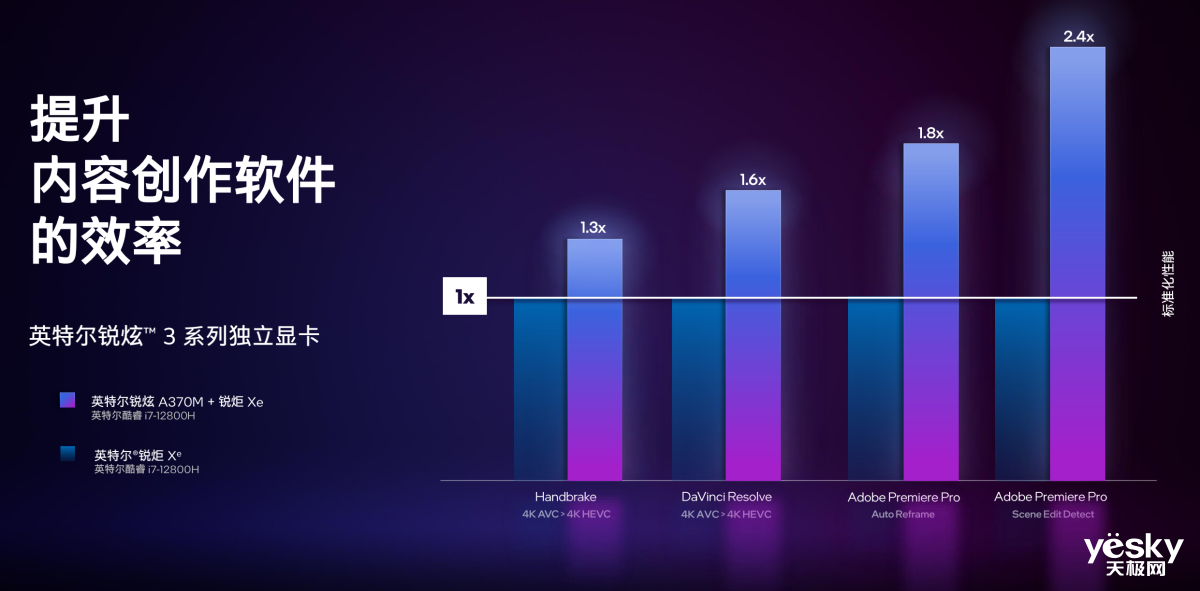
相比没有独显的搭载酷睿i7-12800H的笔记本,配备锐炫A370M后,HandBrake 4K编解码性能提升30%;Davinci Ressolve的4K H.264转H.265性能提升可达60%;Adobe PR内容创作时性能提升更是可以达到140%。当然这些提升不仅是锐炫独显带来的,还离不开系统的DeepLink技术加持。
这也是英特尔选择率先发力面向笔记本的移动端市场的原因之一。英特尔表示:平台级创新是英特尔一直以来的优势,不仅仅是性能优势,在笔记本等移动端平台上英特尔可以提供更多的差异化特性,为用户提供更出色的使用体验。
这里就要提到英特尔为锐炫独显带来的一系列全新特性。
Deep Link
英特尔Deep Link目前包含动态功率共享,超级编码和超级算力三项主要技术。动态功率共享技术可以在系统功耗的限制范围内,尽可能最大化释放CPU和GPU性能。也就是说可以灵活调用CPU、GPU,避免“一个躺平、一个卷死”的情况出现。超级编码技术的作用主要是提升编解码效率,通过OneVPL的API可以同时调用锐炫独显、锐炬核显的硬件编解码能力。

超级算力技术同样可以提升内容创作效率,凭借Open Vino中的MLS(机器学习服务)框架把负载合理的分配给不同计算引擎,根据工作负载的延迟敏感度、吞吐量、性能等特性,智能分配负载到独显、核显以及CPU。MLS会在负载运行过程中不断派发任务,直到得到最终成果。
据英特尔介绍,Deep Link能够为内容创作加速,其中动态功率共享可以带来30%的性能提升;超级编码可以带来60%的性能提升;集合XMX的超级酸粒可以带来24%的性能提升。
AV1
在内容创作方面,锐炫显卡还有一个重要优势。锐炫显卡的媒体引擎内置了非常广泛的编解码器,包括H.265/HEVC、H.264/MPEG-4/AVC、VP9等,同时锐炫显卡也是首个支持AV1硬件编解码加速的GPU,可以带来内容创作效率的提升。据介绍,AV1比H.264编解码器高出50%,比HEVC高出20%,因此能够以更低带宽和更小文件提供更高质量的画面。而且AV1是完全开放没有任何授权费用的编解码器。锐炫显卡中的AV1编码硬件加速与传统软件实现相比,编码速度提高了50倍。目前,包括FFMPEG、Handbrake、Adobe和XSplit都已集成了对锐炫AV1的支持。

游戏优化
说了半天内容创作,下面我们回到玩家们关注的游戏。
在此之前我们要先了解锐炫显卡的特性,或者其核心“Xe HPG微架构”。Xe HPG微架构中每4个Xe内核组成一个渲染切片,所谓渲染切片(Rendering Slice)就是英特尔可重用IP的基本构建块。而组成渲染切片的Xe内核中都配备了相当数量的矢量引擎XVE,矩阵引擎XMX等运算单元,此外,Xe HPG也集成了图形技术,如网格着色,采样器反馈等。

由此也可以看出,Xe HPG微架构拥有很强的灵活性,英特尔可以通过叠加渲染切片来构建不同的SoC,最大可以做到8个,从而针对不同产品线提供丰富的产品。与此前的Xe LP微架构相比,Xe HPG每瓦性能提升了1.5倍。同时,渲染切片支持DX12 Ultimate,其中包括对所有图形固定功能块的改进,并且还有支持微软DXR和Vulkan RT的专用硬件光追单元。每个切片还配备了4个硬件光追加速器,用来支持实时光线追踪技术,能够显著提升3A大作的游戏画面表现和光影效果。
Xe HPG的核心是Xe内核,作为Xe HPG微架构的组成模块,取代了此前集成显卡中EU(执行单元)。Xe内核包括16个256位宽的SIMD矢量引擎,为传统图形着色器执行大部分运算。矢量引擎主要负责传统图像处理的计算任务。而由于AI算法核心几乎完全围绕着一系列大型矩阵乘法和累加算法,英特尔在每个Xe内核构建了专用矩阵引擎来进行硬件加速。Xe内核包含16个矩阵引擎,每个引擎都是1024位宽。

矩阵引擎专为加速AI运算而生。同时为了满足矩阵、矢量和光线追踪单元的高带宽需求,英特尔在每个Xe内核中构建了一个192KB的大型本地内存。它可以根据每个工作负载的需要在L1缓存和共享本地内存(SLM) 之间动态分配。
英特尔借助数据如何通过每个引擎流动,介绍了矩阵引擎的优势和规模。MAC是图形中使用的基本SIMD矢量指令,是矢量引擎的核心。 Xe-HPG执行8次并行运算乘法,然后执行8次并行加法(每个时钟总共16个Ops)。途中前排和后排的方框代表操作数,上下的方框代表累积的源和结果。DP4a是针对不需要32 位精度的AI计算所做的优化,工作原理是将所有32位输入分成8位块,然后独立的乘以这些块,总共是32次并行乘法(由紫色方块显示)。 接下来是32次累加或每个周期总共64次操作(比标准SIMD MAC性能提高了4倍)。矩阵引擎通过将乘法累加4深度流水线化,将其提升到一个新的水平。 与DP4a一样,每个操作数都被分成4个块,这些块被独立的相乘和累加――每个阶段64个操作(由紫色图块显示)。 通过4个阶段,每个时钟产生256次操作(比传统的32位SIMD MAC性能增加了16倍)。

谈到矢量引擎,英特尔为了给浮点运算(FP)提供专用执行端口,对ALU(算术逻辑单元)进行了改进。FP指令现在可以与整数运算(INT)指令同时运行,其中包括DP4a的快速INT8计算。同时英特尔还强化了AI能力,增加了新的XMX矩阵引擎用于高吞吐量矩阵乘法,涵盖最常见的AI数据类型,包括BF16和INT8。

为了有效提高执行性能和算力,Xe-HPG可以同时调度和执行浮点FP、整数INT和XMX指令,并以锁步形式并行两个引擎和共享资源。

那么矢量引擎、矩阵引擎都有什么用?先提一个大家都很熟悉的英特尔超级采样技术XeSS。矩阵引擎的一个主要应用是在实时渲染过程中调用AI,由此英特尔推出的XeSS,和NVIDIA的DLSS有点类似,使用神经网络辅助运动矢量,从低分辨率渲染中生成高分辨率图像。所以XeSS可以在提升分辨率的同时,保证更高的性能,减少游戏卡顿。例如,让游戏能够以原生1080p分辨率的性能渲染游戏帧,然后通过XeSS实现接近原生4K分辨率的画质。

目前,支持XeSS的游戏总计有14款,未来数月还会有更多游戏实现对XeSS的支持。
在提升游戏体验方面,锐炫显卡不仅支持Adaptive Sync技术,英特尔还推出了全新的Speed Sync、Smooth Sync技术,可以适用于任何显示器并解决不同问题,比如显示器与游戏画面刷新率不同步、延迟增加等等。Speed Sync通过关闭V-Sync来改善画面不同步等问题,始终显示最后一个渲染帧的整体,而不是撕裂。Smooth Sync技术通过运用模糊化两个撕裂帧之间的边界来减少视觉失真,解决V-Sync已关闭后渲染更新与面板的刷新周期不同步的问题。

在发布锐炫A系列显卡新品的同时,英特尔也推出了全新锐炫显卡控制面板――ARC Control。用户无需登录就可以通过ARC Control完成显卡的驱动升级、查看显卡性能负载(对于台式机还可支持性能调整)、虚拟摄像头设定、自动生成游戏高光时刻、提供易用的直播功能以及串流相关的功能和设置。ARC Control还会提供性能检测功能,并以具体的参数和可视化图标提供给用户参考。目前,ARC Control已经开放下载,除锐炫显卡外也支持英特尔锐炬核显。另外,如果你想偷懒,可以开启ARC Control的自动更新服务,及时收获新的游戏和驱动信息。

写在最后
虽然是重回独显市场,但多年来英特尔在显卡领域也有布局,通过此前发布的锐炬核显,已经表现出英特尔基于平台级优势,通过升级显卡带来的使用体验升级,比如让搭载锐炬核显的轻薄本提供入门级游戏体验。所以这一次发布高端的锐炫独显,英特尔可谓是“来势汹汹”,凭借对于“双i”的把控,英特尔在技术方面的深耕,还有英特尔与游戏开发者、软件开发者等生态伙伴的深度合作,让锐炫独显无论是在游戏性能,还是在内容创作效率都相当值得期待。
英特尔锐炫显卡会不会成为显卡市场的“鲶鱼”就让我们拭目以待吧。




取消
©2026 天极网旗下网站